Semantic Scene Graphs for Creating a Localization-Ready Internet of Things
Abstract
Controlling devices connected to the Internet of Things often requires juggling multiple smartphone apps or physical remote controls, creating a fragmented user experience. Augmented Reality (AR) can afford superior control by automatically presenting virtual user interfaces that are spatially aligned with networked devices. However, before such user interfaces can be delivered, physical devices must be localized in the environment. This paper introduces LORIOT (LOcalization-Ready Internet Of Things), a novel end-to-end system that uses a semantic scene graph and a large language model to map the identities of the networked devices to physical objects, given a pre-filtered set of IoTdevice candidate nodes. A declarative UI specification enables automatic generation of device control panels for AR and non-AR clients. We evaluate the mapping component on a controlled synthetic-room benchmark of 100 randomly generated rooms. Using device network metadata alone, we achieve a baseline macro-averaged F1 score of 0.80 for digital → physical associations. When device metadata is enriched with physical attributes (mounting location, materials, color, and size), performance improves to 0.88. Moreover, we evaluate the benefit of spatially registered AR control in a within-subject user study (N=20), comparing in-situ AR panels against conventional non-AR control with smartphone apps or physical remote controls. AR yields significantly faster task completion, lower mental demand, and higher usability.
System Overview

LORIOT runs as a distributed system with three main components communicating over a local WiFi network: the device server, the IoT devices, and two types of clients — an AR client (Meta Quest 3) and a smartphone client for non-AR comparison.
The server contains most of the system logic, built on Node-RED, Mosquitto (MQTT broker), and CouchDB. It first constructs a semantic scene graph (SSG) from an RGB-D scan of the environment, then invokes a large language model to compute the device mapping and generate user interfaces. It also routes all commands triggered by the user to the IoT devices via MQTT.
LLM-Based Device Mapping
The core of LORIOT is an LLM-based mapping between network-side device identities and objects in the semantic scene graph. Given a pre-filtered set of IoT-device candidate nodes, the LLM reasons over the SSG together with network-side device metadata to associate each physical object with the correct digital device identity.
The system computes two directional association relations with confidence scores: digital→physical (predicting candidate objects for each device) and physical→digital (predicting candidate device identities for each object).
Automatic UI Generation

LORIOT uses a declarative JSON specification that serves a dual purpose: it provides a manufacturer-independent abstraction for device control and contains the semantic information necessary for an LLM to automatically generate interactive user interfaces.
The LLM assembles a 2D user interface panel with a matching widget (toggle buttons, sliders, push buttons, etc.) for every attribute and command in a device's metadata record. The same JSON specification drives both the AR client (spatially registered panels in Unity on Meta Quest 3) and the smartphone client (a conventional 2D Flutter app), ensuring consistent interfaces across platforms without any per-device code changes.
Evaluation Results
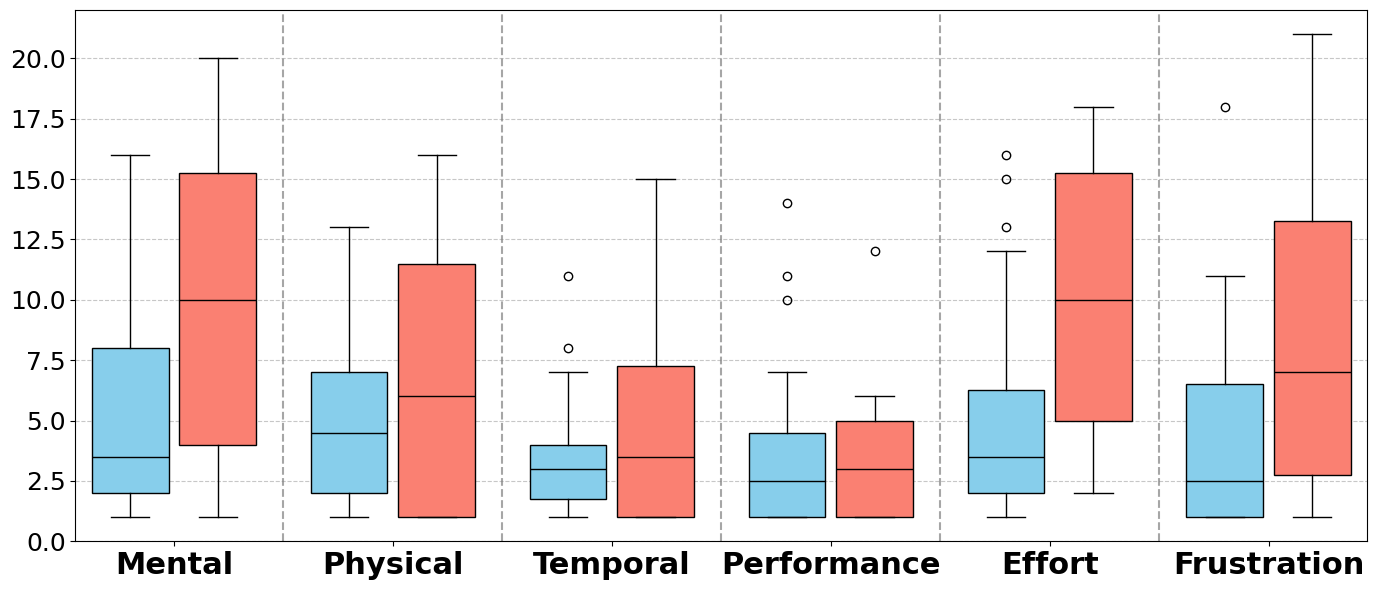
LORIOT was evaluated in two ways. First, a controlled synthetic benchmark of 100 randomly generated rooms measured mapping accuracy. Using device network metadata alone, the system achieved a macro-averaged F1 score of 0.80 for digital→physical associations. When device metadata was enriched with physical attributes (mounting location, materials, color, size), performance improved to 0.88.
Second, a within-subject user study with 20 participants compared AR control against conventional non-AR control with smartphone apps and physical remotes. AR yielded significantly faster task completion (39.2s vs. 68.2s, p=0.003), lower mental demand, lower effort, lower frustration, and higher usability (SUS 84.3 vs. 62.9, p=0.009). Participants overwhelmingly preferred AR for efficiency (18 vs. 2) and fun (18 vs. 2).
BibTeX
@article{kolberg2026loriot,
title={Semantic Scene Graphs for Creating a Localization-Ready Internet of Things},
author={Kolberg, Jan and Pabst, Michael and Biener, Verena and Mori, Shohei and Schmalstieg, Dieter},
journal={IEEE Transactions on Visualization \& Computer Graphics},
year={2026},
url={https://doi.ieeecomputersociety.org/10.1109/TVCG.2026.3698654},
doi={10.1109/TVCG.2026.3698654},
year={2026},
}